Architektur
Jede BI-Lösung braucht eine solide und skalierbare Architektur
An dieser Stelle werden verschiedene Business Intelligence Architekturkonzepte vorgestellt. Für die Realisierung eines konkreten Projekts kann aus diesen Architekturen die passende ausgewählt und an den Kunden angepasst werden.
BI Referenzarchitektur
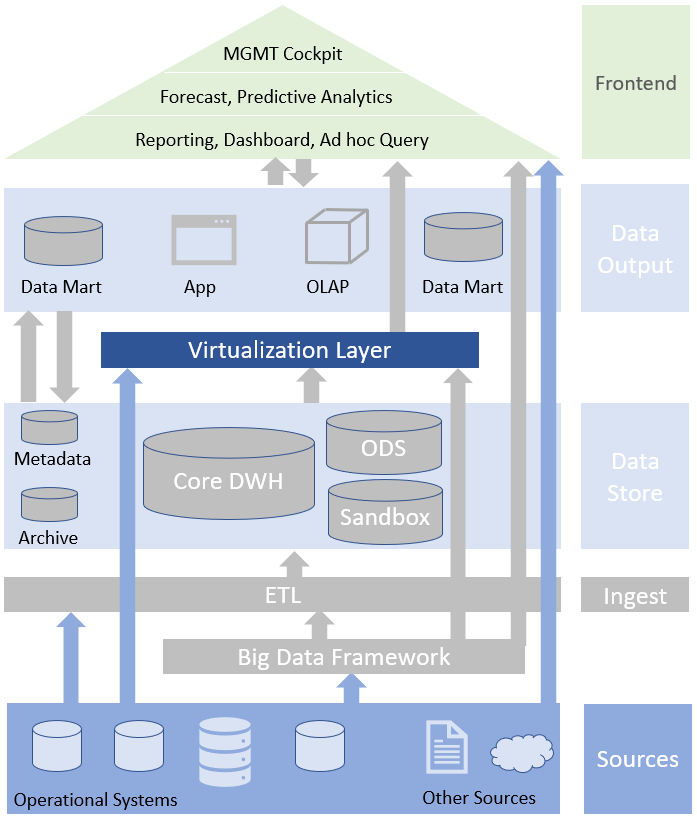
Klassische BI Architektur* mit dem DWH als „Single Point of Truth“. Die Quellen werden über eine Integrationsschicht über ETL-Prozesse in das DWH geladen. Die Verteilung der Daten an die Konsumenten erfolgt über eine Output-Schicht.
DWH (Data Warehouse) = Zentrales Datenbanksystem, das Daten aus verschiedenen Quellen sammelt, bereinigt, speichert und für Analysezwecke zur Verfügung stellt.
ETL = Extraktion, Transformation, Laden. Prozess zum integrieren von Daten aus unterschiedlichen Datenquellen in einem Zielsystem.
ODS = Im Operational Data Store werden die Daten für in der Regel zeitnahe Auswertungen bereitgestellt, die in den Quellsystemen nicht oder nur schwer möglich sind. Differenzierung zu DWH: Keine Historisierung, häufige Aktualisierungen, feinere Datengranularität.
OLAP (Online Analytical Processing) = im Gegensatz zu transaktionsorientierten Systemen (z.B. Buchungen) ein Datenbanktyp zur Haltung von mutdimensionalen Daten (aggregierte Kennzahlen und Dimensionen)
Data Mart: Speziell für eine konsumierendes System (Visualisierung, Anwendung, usw.) aufbereitetee Datenhaltung (Tabelle, View, usw.).

Next Generation DWH
Erweiterung der Referenzarchitektur um ein Big Data Framework und Zusammenführen aller relevanter Unternehmensdaten durch Datenvirtualisierung*. In der Regel (Teil-)Betrieb in der Cloud.
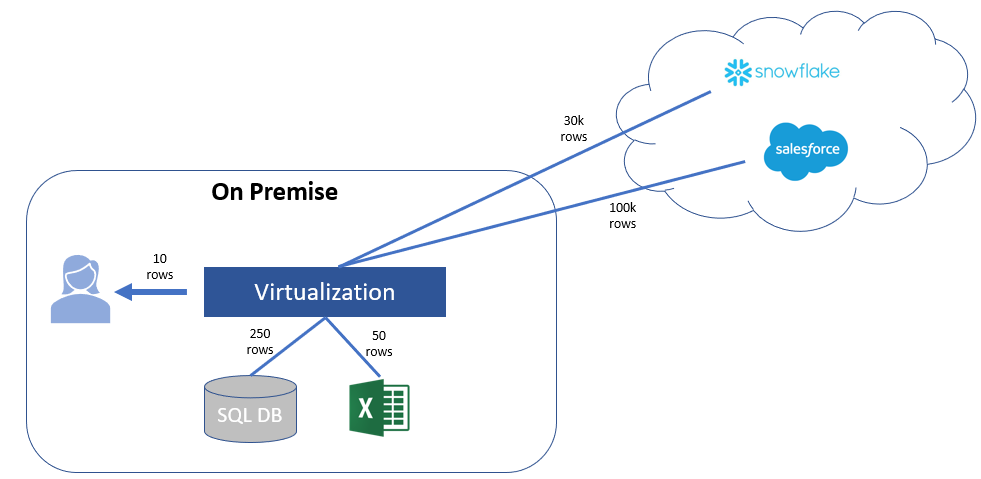
Datenvirtualisierung: Logische Datenschicht, die alle über verschiedene Systeme verteilten Unternehmensdaten (DWH, Data Lake, Quellsysteme, usw.) integriert. Die Daten genügen hierbei der Sicherheit und Governance Kriterien und können in Echtzeit zur Verfügung gestellt werden.
Big Data Framework: Systeme die es erlauben große Mengen von strukturierten und unstrukturierten Daten zu speichern und darauf intensive Rechenprozesse auf Rechnerclustern durchzuführen
Logical Data Warehouse (LDWH)
Etwas andere Darstellung** der vorherigen Architektur. Hier werden alle Datenspeicherungselemente (DWH, Data Lake, usw.) parallel dargestellt. Ingest-Bus/Schicht ermöglicht das Kommunizieren der Datenspeicherungsschichten untereinander.
Der Job des LDWH ist die Integration der neuen und alten Informationssysteme und Bereitstellung über eine zentrale Zugriffsschicht.

Die Welt ist Hybrid
DWH Modernisierung ist häufig das Mittel der Wahl. Zum Beispiel ist ein DWH bereits vorhanden, soll aber um ein Data Lake ergänzt werden und über eine Virtualisierungsschicht vereinigt und für Analysen zur Verfügung gestellt werden.
Die Verknüpfung von DWH-Daten mit unstrukturierten Data Lake Rohdaten mit Web Service Daten mit Excel-Quellen ist möglich. In der Regel müssen die Daten trotzdem für/von den Konsumenten aufbereitet (Bereinigen, Aggregieren, Mapping, Filter, Join Reglen, usw.) werden.
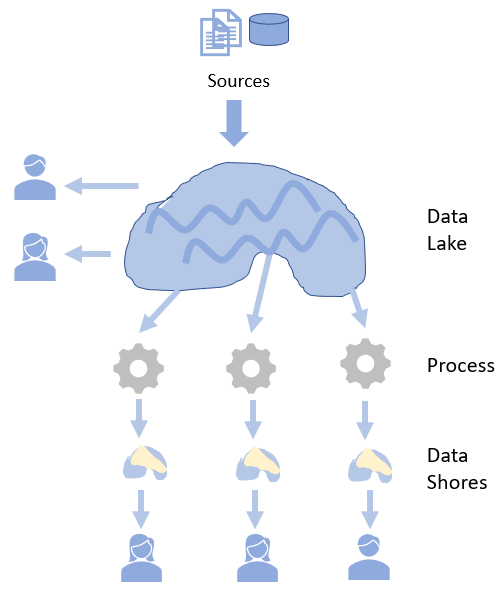
Data Lake
Ein Data Lake ist ein Datenspeicher, der die Daten aus den unterschiedlichsten Quellen in ihrem Rohformat speichert. Er kann sowohl unstrukturierte als auch strukturierte Daten enthalten und bietet die Möglichkeit die Daten zu analysieren. Analysten und Data Scientisten nutzen diese Quellen um mit entsprechenden Algorithmen Zusammenhänge in den Daten zu finden und Prognosen zu erstellen.
In der Regel besteht ein Data Lake Ökosystem aus einem Zoo an Tools und Anwendungen und ist Aufwändig zu betreiben. Es gibt aber auch darauf spezialisierte Derivate, z.B. Cloudera.
Das große Problem von Data Science/Data Lake Projekten ist ein Vorgehen ohne klare Ziele oder zumindest Meilensteine die regelmäßig geprüft neu bewertet werden müssen. Häufig wird Budget zur Verfügung gestellt und das Projektteam bekommt folgende Aufgabe: „Hier habt ihr x-Budget, der Zugriff auf alle Quellsysteme ist beantragt, zieht euch die Daten und findet einen Mehrwert für das Unternehmen“. Dieses Phänomen ist in diesem Video von Jana Schaich Borg von der Duke Universität sehr schön beschrieben: Rock Projects
Unterscheidung DWH und Data Lake***
Anders als bei einem DWH liegt das Problem der Nutzung/Interpretation der Daten beim Konsumenten. Der Analyst/Data Scientist ist für das Aufbereiten, die Interpretation und die Auswertung der Daten verantwortlich. Data Shores dienen als Zugriffsschicht auf Teile der Daten im Lake.
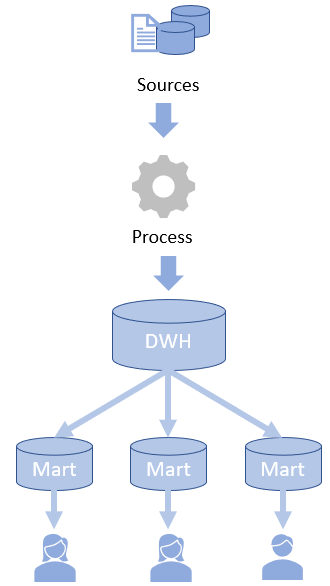
DWH
Data Lake
Data Vault
„Die einzige Konstante im Leben ist die Veränderung“ [Heraklit]
„Es ist nicht die stärkste Spezies die überlebt, auch nicht die intelligenteste. Es ist diejenige, die sich am ehesten dem Wandel anpassen kann“ [Charles Darwin]
Data Vault**** ist eine DWH Modellierungstechnik die es erlaubt mit stetigen Änderungen (technische und fachliche) umzugehen. Data Vault ist somit die Ideale Lösung für ein stabiles und skalierbares DWH.
Gründe für Data Vault
- Änderungen (Iterative Entwicklung)
DWH Änderungen sind aufwändig und teuer (Reengineering, Regression und Impact Test). Z.b. Änderungen an Faktentabelle bedeutet enormen Testaufwand. Fachliche Änderungen sind aufwändig. Schwer entkoppelbare Logik. ‚Single Point of Truth‘ wird in Frage gestellt.
Mit dem Data Vault Ansatz und der damit verbundenen starken Entkoppelung bleibt der Änderungs/Erweiterungsaufwand konstant – unabhängig von der Größe des DWH. Kein Reengineering nötig. - Automatisierung
Im klassischen DWH ist Kaum Automatisierung möglich.
Data Vault ermöglicht einfache ETL-Standardisierung und dadurch die Möglichkeit von ETL-Templates oder ETL-Generatoren. - Performance und Parallelisierbarkeit
Komplexe und gekoppelte Lade-Netze im üblichen DWH. Keine Parallelisierung und dadurch häufig keine Hardwareauslastung.
Data Vault bietet hoch-performante Lade-Prozesse. Durch Entkoppelung der Entitäten kann gut im Team gearbeitet werden.
Was ist Data Vault?
- Methoden zur Datenmodellierung
Konzeptionelle Elemente der Modellierung, Entwurfsregeln und Rahmenwerk - Methoden zur Datenverarbeitung
Standards zur Datenintegration, ETL-Templates und Automatisierung mit Generator möglich - Architektur
Mehrere Schichten trennen Integrations- / Historisierungslogik und Businesslogik
Funktioniert im Big Data Umfeld - Optimierter agiler Entwicklungsprozess
Unterstützung agiler Vorgehensweisen (iterativ, inkrementell). Entkopplung von Änderungen
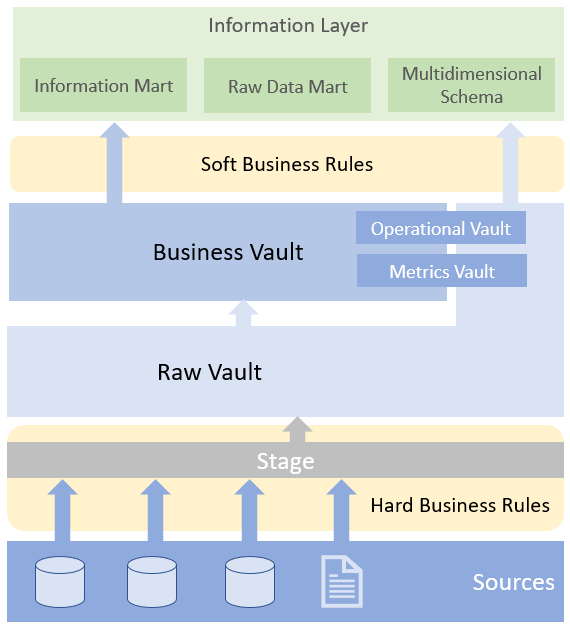
Data Vault Architektur
Das Core DWH besteht aus Raw Vault und Business Vault. Zugrifft erfolgt über den Information Layer.
Stage
Laden der Daten aus den Quellsystemen im Rohdatenformat. Ggf. persistieren der Quelldateien in einem File-Archive, wenn die Daten nicht bereits in einem Data Lake vorgehalten werden.
Raw Vault
Data Vault Modellierung im Rohformat. In der Regel Insert-Only Ansatz. Parallelisierung der Ladeprozesse möglich. Keine Abbildung von Businesslogik. Hard Rules sind möglich.Enthält folgenden Entitäten:
Hub
Eindeutige Geschäftsentität eines Geschäftobjekts (z.B. Artikelnummer)
Enthält Business Key (BK)
Enthält Surrogate-Key (SK) Hash value, dadurch keine Lookups nötig
„Hash Kollisionen sind extrem unwahrscheinlich: Bei 6 Billionen neuen Hashes pro Sekunde ist im Mittel nach 100 Jahren mit einer Kollision zu rechnen (Modell: Birthday Paradox)“
Link
Verbindet mehrere Geschäftsobjekte (z.B. Artikel mit Bestellung)
Enthält eigenen Surrogate Key (SK)
Enthält Surrogate-Keys der Hubs (FK)
Satellite
Attribute eines Geschäftobjekts (Hub oder Link) (z.B. Artikelbeschreibung, Preis)
Enthält Surrogate-Key des Hubs/Links (FK)
Enthält Datum zur Historisierung
Enthält HashDiff zur Identifizierung von Änderungen (Historisierung)
Business Vault (optional)
Abbildung der Business Regeln. Hier werden die fachlichen Anforderungen abgebildet indem die Daten interpretiert und entsprechend aufbereitet (Aggregation, Transformation, Filter, Verknüpfung, usw.) werden.Höhere granularitätsebene. Ist sehr flexibel und Kann unter anderem folgende Elemente enthalten:
Point In Time Table –auch in RV- (Zwecks Performance Optimierung. Zusammenfassung eines Hubs mit seinen Satelliten mit deren Ladedatum. Neuer Eintrag wenn sich die letzte Version eines Satellites ändert.)
Bridge Table –auch in RV- (Zwecks Performance Optimierung. Ein modifizierter Link zur Verknüpfung mehrere Hubs. Enthält die Keys zu den Hubs/Links um den Zugriff zu ermöglichen. Kann auch Business Keys enthalten.)
Predefined Derivations/Calculation (Enthält berechnete Werte zur einheitlichen Definition von Kennzahlen. Z.B. min, max und avg Einkaufkosten von Artikeln pro Monat)
Information Mart Layer
Zugriffsschicht für Konsumenten.
- Raw Data Mart (Zugriff auf Raw Vault-Strukturen)
- Star Schema (Multidimensionales Modell mit Fakten und Dimensionen)
- Information Mart (aufbereiteter Mart)
Metainformationen
Informationen
- Metriken zur Ausführung
- Basis für Impact Analyse
- Fehler Marts
- Datenqualität Marts
Abgrenzung zur klassischen DWH Architektur
Klassische DWH Architektur
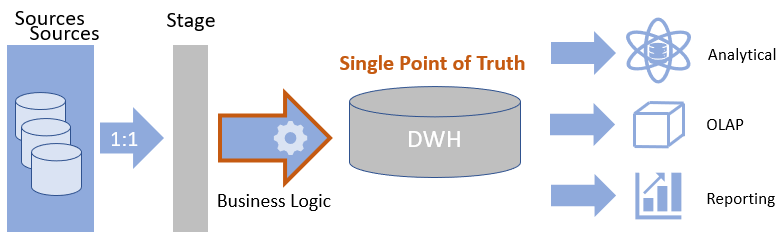
- Business Regeln greifen vor DWH Befüllung
- Integrationslogik und Businesslogik sind direkt gekoppelt
Data Vault Architektur
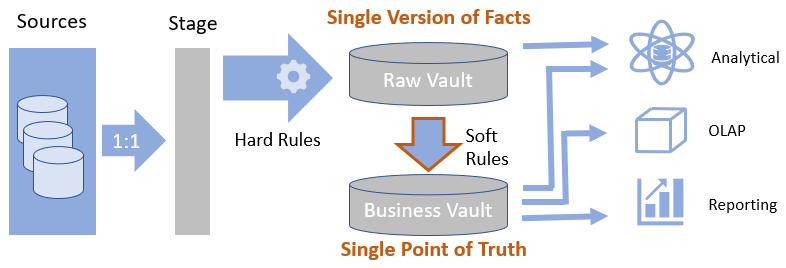
- Business Regeln greifen nach DWH Befüllung
- Hard Rules: Keine Änderung von Bedeutung und Inhalt. (z.B. Zusammenführung von 3 Feldern zu einem Schlüsselfeld für SK, Datentypkonvertierungen). Dokumentation der Hard Rules ist wichtig.
- Soft Rules: Anwendung Business Logik, Filter, Aggregationen, Transformationen, usw.
- Business Vault bietet ‚Single Point of Truth‘ (Erstellung wiederverwendbarer Kennzahlen)
- Konsumenten greifen in der Regel auf Business Vault zu
*Mit Anlehnung an: Tom Gansor und Andreas Totok (Von der Strategie zum Business Intelligence Competency Center (BICC))
**Mit Anlehnung an Henry Cook von Gartner (Adopt the Logical Data Warehouse Architecture to Meet Your Modern Analytical Needs)
***Bilder von Martin Fowler (DataLake)
****Data Vault wurde von Dan Linstedt entwickelt
****Data Vault 2.0 Guide: Data Vault Modeing Guide
****Data Vault Blog von Kent Graziano